Introduction
Semantic search is a type of search that goes beyond keyword matching to understand the meaning of the query and the documents being searched. This allows semantic search engines to return more relevant results to users, even if the query does not contain the exact keywords that are present in the documents.
Why is semantic search important?
Semantic search is important because it allows users to find the information they need more easily and efficiently. Traditional keyword-based search engines can only match exact keywords, which can lead to irrelevant results. Semantic search engines, on the other hand, can understand the meaning of the query and the documents being searched, which allows them to return more relevant results, even if the query does not contain the exact keywords that are present in the documents.
In this blog post, we will discuss the benefits of using semantic search and how to implement it using Haystack, Qdrant, sentence-transformers/multi-qa-MiniLM-L6-cos-v1, and tiiuae/falcon-7b.
What are Haystack, Qdrant, sentence-transformers/multi-qa-MiniLM-L6-cos-v1, and tiiuae/falcon-7b?
Haystack
Haystack is an open source Python framework for building and deploying semantic search solutions. It is built on top of popular open source libraries such as NumPy, TensorFlow, and Elasticsearch. Haystack provides a number of features that make it easy to build semantic search systems, including:
- A variety of pre-trained encoders and retrievers that can be used to generate embeddings and index documents.
- A modular architecture that allows users to customize their search pipelines by adding or removing components.
- A number of pre-built pipelines for common tasks such as question answering and document search.
- A REST API that allows users to deploy their search pipelines as web services.
Some of the benefits of using Haystack for semantic search:
- Ease of use: Haystack is easy to use, even for users with limited experience in machine learning or natural language processing.
- Flexibility: Haystack is a flexible framework that allows users to customize their search pipelines to meet their specific needs.
- Performance: Haystack is a high-performance framework that can be used to build scalable and efficient semantic search systems.
- Open source: Haystack is an open source framework, which means that it is free to use and modify.
The overall architecture of haystack is 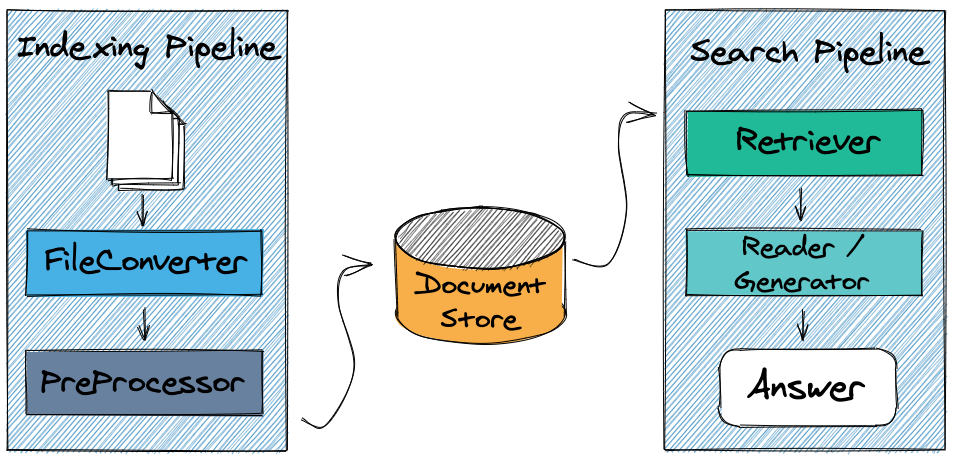
For more information you can check their website: https://haystack.deepset.ai/overview/intro
Qdrant
Qdrant is an open-source vector database that is optimized for semantic search. It is a distributed database that can scale to handle large datasets. Qdrant provides a number of features that make it ideal for semantic search, incl-uding:
- Support for a variety of vector similarity metrics, such as cosine similarity and Euclidean distance.
- Efficient nearest neighbor search algorithms.
- Support for filtering and sorting results.
- A REST API that makes it easy to integrate Qdrant with other applications.
Some of the benefits of using Qdrant for semantic search:
- Performance: Qdrant is a high-performance database that can efficiently handle large datasets and complex queries.
- Scalability: Qdrant is a distributed database that can scale to handle even the most demanding workloads.
- Ease of use: Qdrant is easy to install and use, even for users with limited experience in database administration.
- Open source: Qdrant is an open source database, which means that it is free to use and modify.
Encoder model - sentence-transformers/multi-qa-MiniLM-L6-cos-v1
The model sentence-transformers/multi-qa-MiniLM-L6-cos-v1 is a pre-trained sentence transformer model that can be used for semantic search. It is trained on a massive dataset of text, and it is capable of learning the meaning of sentences and paragraphs.
The model works by encoding sentences and paragraphs into vector representations. These vector representations capture the meaning of the text, and they can be used to compare sentences and paragraphs to each other.
The sentence-transformers/multi-qa-MiniLM-L6-cos-v1 model is specifically designed for semantic search. It is trained on a dataset of question-answer pairs, and it is able to learn the relationships between questions and answers. This makes it ideal for tasks such as question answering and document retrieval.
The model is also very efficient, making it suitable for large-scale applications. It can be used to encode and compare millions of sentences in seconds.
Some of the benefits of using the sentence-transformers/multi-qa-MiniLM-L6-cos-v1 model for semantic search:
- Accuracy: The model is able to accurately encode and compare sentences, even if they are long or complex.
- Efficiency: The model is very efficient, making it suitable for large-scale applications.
- Versatility: The model can be used for a variety of semantic search tasks, such as question answering and document retrieval.
Falcon-7B
Falcon-7B is a 7B parameter large language model (LLM) developed by the Technology Innovation Institute (TII) in Abu Dhabi, UAE. It is trained on a massive dataset of text and code, and it is capable of performing many kinds of tasks, including generating text, translating languages, writing different kinds of creative content, and answering your questions in an informative way.
Falcon-7B is one of the largest and most powerful open-source LLMs available. It is also one of the most efficient LLMs, thanks to its use of a novel architecture that is optimized for inference.
Falcon-7B can be used for a variety of tasks, including:
- Text generation: Falcon-7B can generate realistic and coherent text in a variety of styles, including news articles, blog posts, poems, and code.
- Translation: Falcon-7B can translate between a variety of languages, including English, Arabic, French, and Chinese.
- Question answering: Falcon-7B can answer a wide range of questions, including factual questions, open-ended questions, and challenging questions.
- Summarization: Falcon-7B can summarize long and complex texts in a concise and informative way.
- Creative writing: Falcon-7B can generate creative text formats of text content, like poems, code, scripts, musical pieces, email, letters, etc.
Falcon-7B is a powerful and versatile tool that can be used for a variety of tasks. It is still under development, but it has the potential to revolutionize the way we interact with computers.
In this blog I will explain you how you can use this model to summarize the relevant documents that are returned by the qdrant.
How to use Haystack, Qdrant, sentence-transformers/multi-qa-MiniLM-L6-cos-v1, and Falcon-7B for semantic search
Simple workflow of how every component will be used for semantic search is shown below
The system works as follows:
- The user enters a query into the user interface.
- The haystack searches the qdrant document store for documents that are relevant to the query by converting the query to 384 vector embedding by using
sentence-transformers/multi-qa-MiniLM-L6-cos-v1. - Relevant documents from Qdrant are then provided to Falcon LLM with the user question and a prompt to summarize the documents based on question.
- The generated answer is then sent back to haystack and then to user.
Code walk-through
The code is divided into two parts:
- In the first part we are creating the embeddings and storing it in disk.
- In the second part we will only query the data that is stored in the qdrant.
Part one: Storing Embeddings for Semantic Search
Install the required modules
pip install qdrant-haystack
pip install farm-haystack[inference]
Make qdrant up and running using the below command
docker run -p 6333:6333 -v qdrant_storage qdrant/qdrant
Note: Here we are storing the embeddings in the qdrant_storage directory so that we don’t need to generate them every time.
Importing the required modules
from qdrant_haystack import QdrantDocumentStore
from haystack import Document
from haystack.nodes import EmbeddingRetriever
Initialize the Qdrant document store
document_store = QdrantDocumentStore(
"localhost",
port = 6333,
index="test_data",
content_field = "content",
name_field = "name",
embedding_field = "vector",
embedding_dim=384,
recreate_index=True,
hnsw_config={"m": 16, "ef_construct": 64},
on_disk_payload = True
)
A few points that are important in the above code are:
index = "test_data"This represents under which file collection the data will be stored or retrieved.embedding_dim = 384The modelsentence-transformers/multi-qa-MiniLM-L6-cos-v1generates embeddings of dimension 384 so we need to provide tell qdrant that the current collection will only store embedding of 384.on_disk_payload = TrueThis enables the embeddings to be stored on disk.
Download the dataset using and extract it
wget https://s3.eu-central-1.amazonaws.com/deepset.ai-farm-qa/datasets/documents/wiki_gameofthrones_txt1.zip
Read the dataset downloaded above
from os import listdir
doc_dir = "wiki_gameofthrones_txt1" # Path to extracted directory
files_to_index = [doc_dir + "/" + f for f in listdir(doc_dir)]
docs = []
for file in files_to_index:
with open(file, "r", encoding='utf-8') as f:
text = " ".join(f.readlines()).strip()
doc = Document(text=text, content=text, meta={"file_name": file})
docs.append(doc)
Write documents to qdrant
document_store.write_documents(docs)
Initialize the retriever and create the embeddings
retriever = EmbeddingRetriever(
document_store=document_store,
embedding_model="sentence-transformers/multi-qa-MiniLM-L6-cos-v1",
model_format="sentence_transformers",
)
document_store.update_embeddings(retriever)
Part two: Retrieving Documents with a Embedding Retriever
Note: The following code can be in a completely different file or you can create Fast api endpoints using the below code
Import the required modules
from qdrant_haystack import QdrantDocumentStore
from haystack.nodes import EmbeddingRetriever
from haystack.nodes import PromptNode, PromptTemplate, AnswerParser
from haystack.pipelines import Pipeline
from transformers import AutoModelForCausalLM
from transformers import AutoTokenizer
Initialize the document store
document_store = QdrantDocumentStore(
"localhost",
port = 6333,
index="test_data",
content_field = "content",
name_field = "name",
embedding_field = "vector",
embedding_dim=384,
hnsw_config={"m": 16, "ef_construct": 64},
on_disk_payload = True
)
Initialize the embedding retriever
retriever = EmbeddingRetriever(
document_store=document_store,
embedding_model="sentence-transformers/multi-qa-MiniLM-L6-cos-v1",
model_format="sentence_transformers",
top_k=2 # This will only return the 2 results that have a high score
)
Note: The embedding model should be the same that was used to create the embeddings.
Initialize the prompt node in haystack for RAG
model = "tiiuae/falcon-7b"
tokenizer = AutoTokenizer.from_pretrained(model)
model = AutoModelForCausalLM.from_pretrained(model, trust_remote_code=True)
rag_prompt = PromptTemplate(
prompt="""Answer the following question \n\n Related text: {join(documents)} \n\n Question: {query} \n\n Answer:""",
output_parser=AnswerParser())
prompt_node = PromptNode(model, model_kwargs={"model":model, "tokenizer": tokenizer}, default_prompt_template=rag_prompt)
Describe how pipeline will work
pipe = Pipeline()
pipe.add_node(component=retriever, name="retriever", inputs=["Query"])
pipe.add_node(component=prompt_node, name="prompt_node", inputs=["retriever"])
Ask question and get the result
query = "who is father of Arya Stark" # input()
output = pipe.run(query=query)
print(output["answers"][0].answer)
Conclusion
Semantic search is a powerful new technology that has the potential to revolutionize the way we search for information. It is still under development, but it has already been used to build a variety of successful applications, such as search engines, question answering systems, and document retrieval systems.
Semantic search has the potential to make our lives easier and more efficient by helping us to find the information we need more quickly and easily. It can also help us to better understand the world around us by providing us with information that is relevant to our interests and needs.
I believe that semantic search has the potential to make the world a better place. It can help us to find solutions to the challenges we face, and it can help us to build a brighter future for all.